
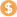


Умные устройства научились понимать направление речи

Американские инженеры разработали алгоритм, позволяющий умным устройствам понимать направление речи человека. Это позволяет не использовать фразы активации, такие как «Окей, Google» или «Привет, Siri», поскольку устройство будет понимать, что пользователь обращается к нему. Статья была представлена на конференции UIST 2020.
Голосовые помощники в умных колонках, смартфонах или ТВ-приставках, как правило, все время слушают пользователя в ожидании активационной фразы и начинают слушать сами команды только после ее произнесения. Но между собой люди общаются проще и используют невербальные признаки, такие как направление взгляда, чтобы понять, что другой человек обращается к ним. Использование таких признаков голосовыми помощниками могло бы упростить их использование в доме, где есть несколько устройств с такой функцией, и некоторые разработчики уже работают над этим. Например, Apple недавно предложила оснащать умные колонки камерами с алгоритмами отслеживания взгляда, чтобы избавить их от активационной фразы и научить понимать, на какие предметы показывает человек. Но камеры потенциально могут раскрыть больше конфиденциальной информации, чем микрофоны, поэтому пока умные колонки в основном работают без них.
Инженеры из Университета Карнеги — Меллона под руководством Криса Харрисона (Chris Harrison) разработали новый метод, который позволяет определять направление речи человека с помощью микрофонов, а не камер.
Принцип работы алгоритма основан на двух особенностях распространения звука при речи. Главная из них заключается в том, что звуки разных частот по-разному распределяются вокруг рта: высокочастотная часть сконцентрирована перед ртом, а по мере удаления от центрального направления интенсивность сильно снижается, тогда как низкочастотные звуки распределены более равномерно. Таким образом, в записанном микрофоном звуке соотношение низких и высоких частот различается в зависимости от направления источника звука. Авторы использовали это для расчета этого направления. Алгоритм отдельно рассчитывает мощность колебаний с частотой до семи килогерц и выше семи килогерц, затем проводит быстрое преобразование Фурье и по соотношению мощностей двух диапазонов определяет угол к микрофону, под которым была произнесена речь.
Вторая особенность, которую использовали разработчики, заключается в том, что при разговоре в помещении возникает небольшое эхо. Соответственно, если человек повернут к микрофону, первый достигший микрофона сигнал будет четким, а за ним могут появиться намного меньшие по интенсивности и четкости повторения. Если же человек отвернут, то все колебания будут дублироваться и искажаться. Алгоритм, созданный разработчиками анализирует форму сигнала в первые 10 миллисекунд после начала речи. Он вычисляет величину наибольшего пика интенсивности звука, сравнивает ее со средним от остальных пиков за этот временной промежуток и определяет, был ли человек отвернут от микрофона.
Инженеры обучили алгоритм, сделав множество записей под разным углом и с разного расстояния, а затем обучив классификатор, работающий на одном из вариантов дерева решений. В результате им удалось достичь точности определения того, обращен ли человек лицом к микрофону, равной 90 процентам. Если алгоритм обучен на конкретном помещении, точность повышается до 93 процентов. Авторы отмечают, что это ниже, чем точность, которую пользователи ожидают от функций серийных голосовых помощников, но выше, чем у разработанных ранее методов.

Точность распознавания направления на микрофон в зависимости от угла
Karan Ahuja et al. / UIST 2020
Источник: rusjev.net/
Читайте ещё:
 1272 1105 1141 1318 1287 1243 1278 1283 1160 1094
1272 1105 1141 1318 1287 1243 1278 1283 1160 1094 